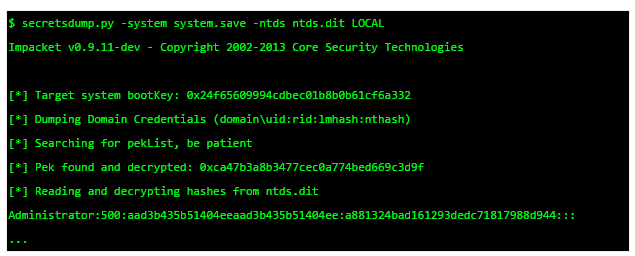
In this last part of the series IPv6 for pen testers we will now cover how address autoconfiguration works without the need for a central DHCP server. I really encourage you to read part 1, 2 and 3 of this series as they cover the IPv6 fundamentals needed to understand the following paragraphs.
In IPv4 a central DHCP server was used to autoconfigure the IP addresses and the standard gateways for all clients. In IPv6 however, routers advertise the on-link networks and the available routes on their own using multicast. That means that as soon as a new client is connected to a network, all the available routers advertise all the avilable network prefixes. The client then assigns itself an IPv6 address within each on-link network and adds all other prefixes to his routing table. The full IPv6 addresses for the on-link networks are created by appending the host portion as generated by the EUI-64 algorithm as discussed in part 3 to the advertised network prefixes. We will now discuss this process in more detail with the help of the following image: 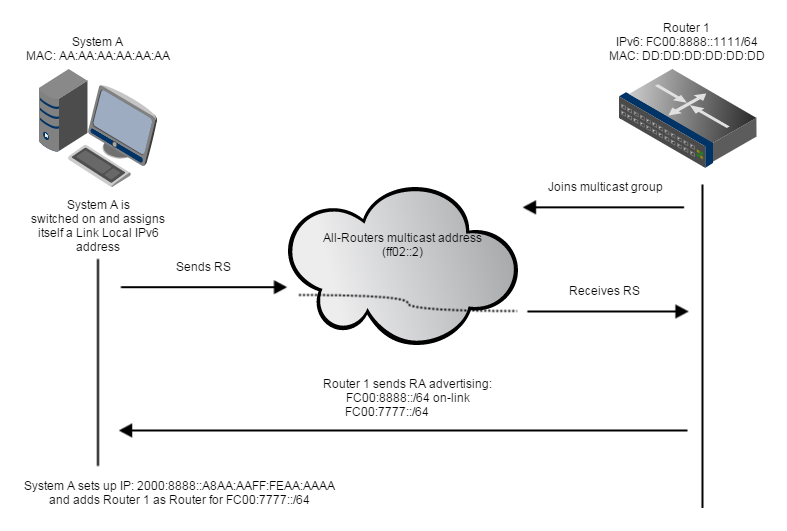
In IPv6 all routers on a network join the so called All-Routers multicast address FF02::2. This group is then used to periodically advertise all available on-link network prefixes and all routable destinations. However as it takes up to two minutes to receive all information a recently booted system can trigger a full re-advertisement of all prefixes by sending a Router Solicitation message to the All-Routers multicast group. After that all routers directly reply with Router Advertisement messages with all on-link and all routable destinations. As already mentioned the client than adds a new IPv6 address for each prefix by appending its EUI-64 host ID. This process allows a client to join a network without any prior configuration.
If it is necessary to provide more information to the clients (like DNS servers) the special “Other configuration” bit can be set in the Router Advertisement message. It indicates that other configuration information is available via DHCPv6. This type of DHCP server is called stateless because it only hand out static configuration and does not track its clients.
Beyond using Stateless Address Autoconfiguration (SLAAC), as this process is called, it is still possible to use a fully featured DHCPv6 server instead.
Router Advertisement Flood
A pen tester specific IPv6 technique was discovered by Sam Bowne, a well known IT security expert. He developed a Denial of Service exploit for all up-to-date operating systems (Linux, Windows and OS X) based on Router Advertisement messages. It works by flooding the network with new route advertisements that get processed by the attacked clients. During this processing the systems get practically unusable. Sam captured several videos to showcase the result of the flood on this website.
Further Reading
Before rounding this series up here are some references for your further reading:
- IPv6 Cheat Sheet: http://www.roesen.org/files/ipv6_cheat_sheet.pdf
- IPv6 Address Calculator: http://silmor.de/ipaddrcalc.html
- Wikipedia IPv6: http://www.wikiwand.com/en/IPv6
- Wikipedia Network Discovery Protocol: https://www.wikiwand.com/en/Neighbor_Discovery_Protocol
- The TCP/IP Guide: http://www.tcpipguide.com
- RFC 2460 – Internet Protocol, Version 6: https://www.ietf.org/rfc/rfc2460.txt
- RFC 4862 – IPv6 Stateless Address Autoconfiguration: https://tools.ietf.org/html/rfc4862
- RFC 4861 – Neighbor Discovery for IP version 6 (IPv6): https://tools.ietf.org/html/rfc4861
- DHCPv6: https://www.wikiwand.com/en/DHCPv6
Roundup
Although already standardized in 1998 IPv6 still has not fully reached the end customers. Only very few ISPs in Europe by default even provide IPv6 address to their customers and even less companies use IPv6 within their networks. However as IPv4 addresses will eventually run out in the not too distant future companies have to prepare their equitement and train their employees. This is especially important as virtually every new network component is IPv6 capable and most of them even have it pre-enabled. As we have learned in this series IPv6 introduces many new concepts and some of them can be misused. I currently advise everyone to disable the IPv6 stack on their network components if not used and I highly recommened companies to train their administrators so that they know how IPv6 works and what challenges it brings with it.



{kind=link}